
AI Bevezető: Mi is az AI, LLM és társaik?
AI Bevezető: Mi is az AI, LLM és társaik?
A legutóbbi blogbejegyzésemben arról beszéltem, hogy meg kell tanulnom tanulni. Már máskor is szívesen alkalmaztam azt a módszert, hogy elmagyarázom valakinek azt, amit épp tanulok, ezáltal jobban elmélyítem magamban azt a tudást. A probléma az volt eddig, hogy ezt nem tudatosan csináltam, mert nem tudtam, hogy ez egy valódi tanulási technika.
Úgy döntöttem, hogy a következő témakört, amiről tanulni fogok, ezzel a módszerrel fogom megtanulni. Szóval ilyen blogbejegyzés formájában fogom megtanulni és továbbadni a tudást, amit felszedek… legalábbis megpróbálom. Azt mondják a nagyok, hogy ha egyszerűen nem tudsz elmagyarázni valamit, akkor valójában nem is érted. Én megpróbálom elég egyszerűen elmagyarázni, hogy megértsem én is.
Az első ilyen sorozat az AI agentek fejlesztéséről fog szólni. A cégnél, ahol dolgozom, egy 12 alkalmas LLM tréninget szerveztek az alkalmazottaknak, én ezzel fogok foglalkozni és ezt fogom majd továbbadni.
Az első bejegyzés, pontosabban ez a bejegyzés, ebben a témában egy rövid AI bevezető lesz, kicsit arról fogok beszélni, hogy mi is az AI, LLM meg hasonlók.
Mi is az a Mesterséges Intelligencia?
Szóval. Ami elsőre nagyon fontos, hogy a mesterséges intelligencia nem egy nagyon új dolog, amit 2020-ban találtak fel, csak ekkor került be igazán a köztudatba a ChatGPT-nek köszönhetően. Az AI mint kutatási terület már évtizedekkel korábban létezett.
A mesterséges intelligencia gyakorlatilag egy gyűjtőfogalom, ami magába foglal olyan technológiai megoldásokat, amelyek során egy gép az emberi kognitív funkciók imitálására lesz képes. Ez például azt jelenti, hogy a gép képes lesz megérteni – pontosabban azt imitálni, hogy érti – az ember által adott információt írott vagy beszélt formában, megérteni egy kép tartalmát, videó tartalmát stb. Később ezeket a gépeket arra használják, hogy bonyolult feladatokat végezzenek el.
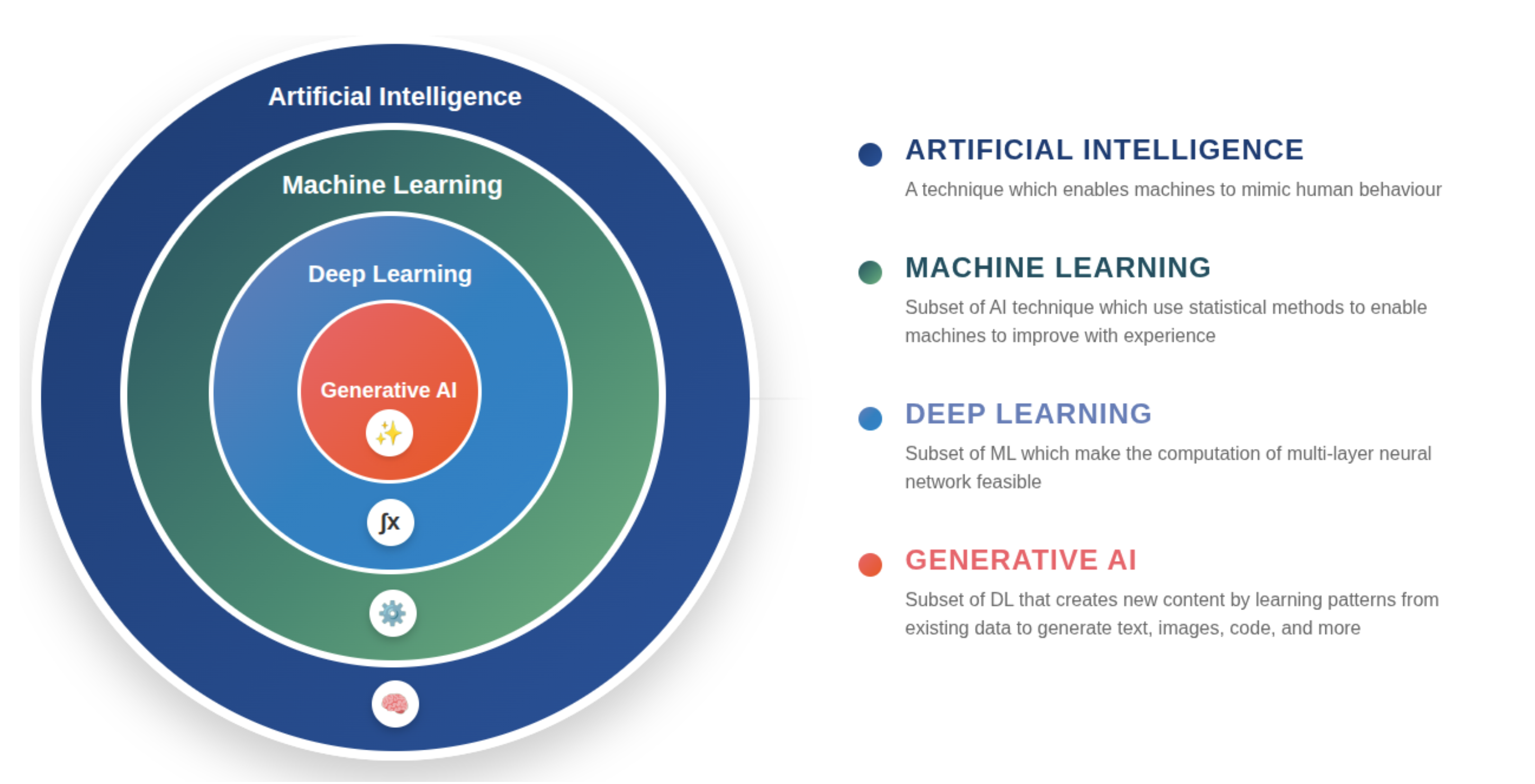
Gépi Tanulás (Machine Learning)
A gépi tanulás az AI egyik területe, ahol a gép adatokból tanul, és a korábbi példák alapján próbál döntéseket hozni. A tanulás eredménye maga a „modell" – ez tartalmazza a megtanult mintákat és szabályokat.
Mélytanulás (Deep Learning)
A mélytanulás (deep learning) a gépi tanulás egy speciális ága, amely neurális hálózatokat használ. Ezek rétegekbe szervezett „mesterséges neuronokból" állnak, amelyek egymásra épülve egyre összetettebb mintákat tudnak felismerni, például kézírt számok felismerése képeken.
Hogyan működik ez a neurális háló?
Ebben a példában egy 28×28 pixeles képet szeretnénk felismerni, amely egy kézzel írt számot tartalmaz. A képet először kilapítjuk, vagyis a 28×28-es mátrixból egy 784 elemű számsort készítünk, ahol minden szám egy pixel értékét jelenti. Ez lesz a neurális háló bemenete. A bemeneti réteg tehát 784 neuront tartalmaz, mindegyik egy-egy pixelhez kapcsolódik, de itt még nem történik „gondolkodás”, csak az adatok továbbadása.
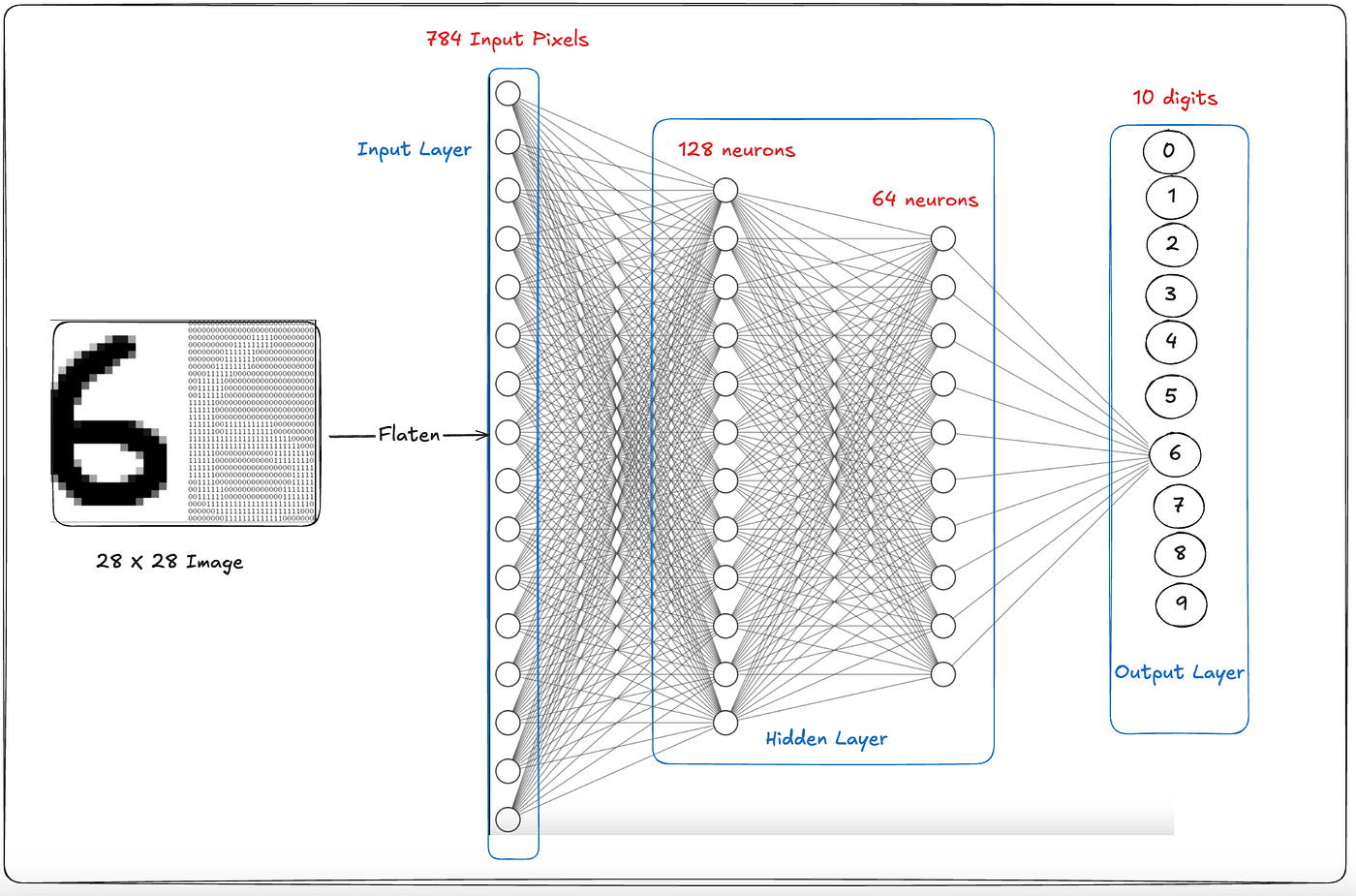
A feldolgozás a rejtett rétegekben történik, ahol a neurális háló megpróbál mintákat felismerni. Ebben a példában két ilyen réteg van: az első 128, a második 64 neuronnal. Itt tanulja meg a rendszer például azt, hogyan néz ki egy ív, egy körvonal vagy egy függőleges vonás, és ezekből hogyan áll össze például egy „6”-os alakja.
A végén a kimeneti réteg következik, ahol 10 neuron található, mindegyik egy számjegyet képvisel 0-tól 9-ig. A hálózat kiszámítja, melyik kimeneti neuron aktiválódik a legerősebben, és ez alapján dönti el, hogy melyik szám szerepel a képen. Ha például a „6”-os neuronnak lesz a legnagyobb értéke, akkor a hálózat úgy gondolja, hogy a képen egy 6-os látható.
A lényeg, hogy a hálózat nem „látja” vagy „érti” a képet emberi módon, hanem sok példán keresztül megtanult minták alapján valószínűségi döntést hoz.
LLM – Large Language Model
El is jutottunk ahhoz a ponthoz, amiről már mindenki hallott. Ez az a része, amit a legtöbben egyszerűen AI-nak hívnak. Az LLM a deep learning egy speciális típusa, amelyet szöveg megértésére és generálására tanítanak. Valójában nem „érti” a mondatot emberi módon, hanem megnézi az addigi szöveget, és statisztikai alapon megtippeli, mi lehet a következő szó vagy kifejezés.
Tokenek és Vektorok
Az LLM nem szavakban gondolkodik, hanem úgynevezett tokenekben – ezek lehetnek teljes szavak, darabokra vágott szórészek vagy akár írásjelek, attól függően, hogyan lett a modell betanítva. Minden token egy nagyon sok dimenziós vektortérben kap helyet, ahol a jelentésben hasonló tokenek közelebb vannak egymáshoz (pl. király – királynő, férfi – nő).
A következő két ábrán láthatjuk, hogyan bontja tokenekre ugyanazt a szöveget két különböző LLM modell.
GPT-4o & GPT-4o mini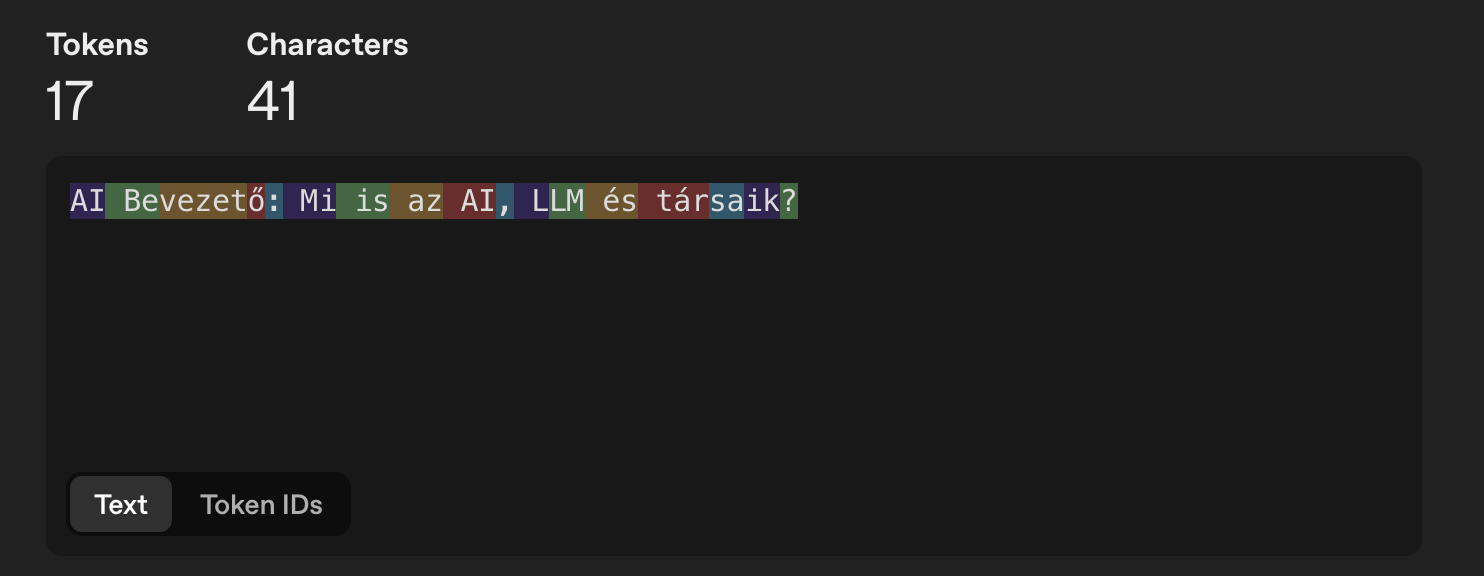
GPT-3.5 & GPT-4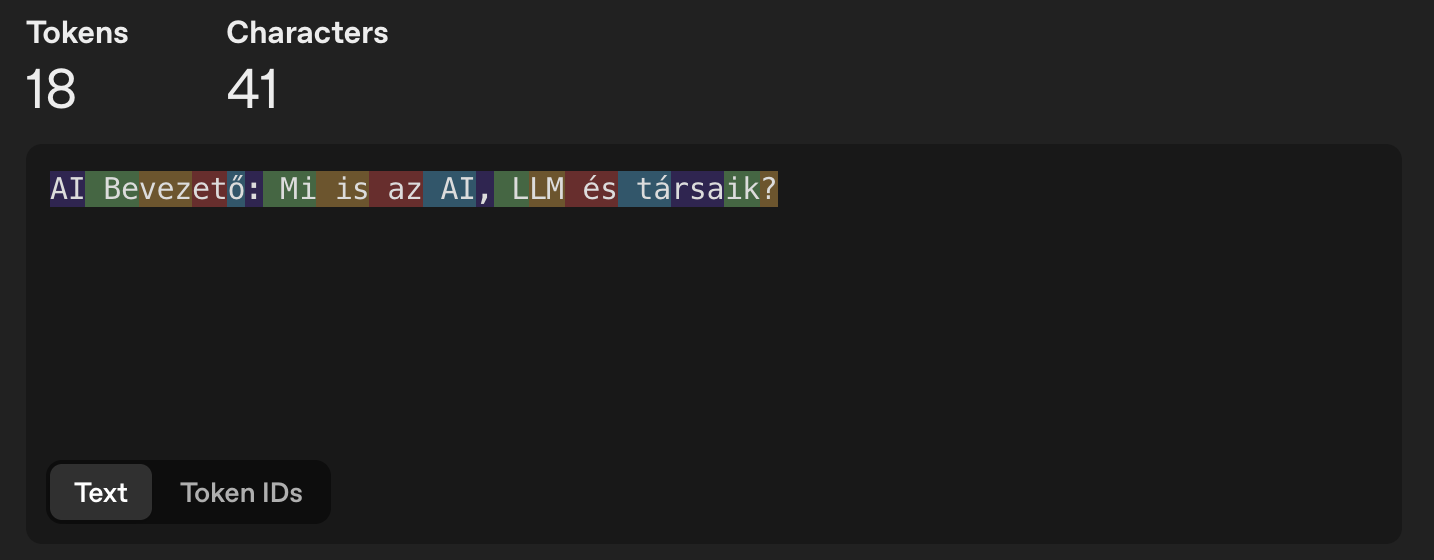
Amikor beszélgetünk az LLM-el:
- a tokenekből vektorok lesznek
- a modell figyelembe veszi a teljes kontextust, nem csak az utolsó szót
- kiszámolja, melyik token a legvalószínűbb folytatás
- egy kiválasztott tokennel folytatja a szöveget
- majd újra és újra ismétli a folyamatot
Összefoglalás
Ez nem fekete mágia, hanem statisztika, matematika és rengeteg adat. Mégis képes gondolkodást és megértést imitálni, mert a hatalmas mennyiségű tanulási adatból egy jól működő modellt hoztak létre.
Remélem, ez a rövid bejegyzés segített nagyvonalakban megérteni, hogyan működik egy ilyen rendszer – mert erre fog épülni a folytatás.
Nekem segített. :D